






Adam-mini 在降低 50% 内存开销的同时保持了与 Adam 优化器相当甚至更优的性能。
作者丨SRIBD
论文《Adam-mini: Use Fewer Learning Rates to Gain More》是关于优化器设计与内存效率提升领域的创新研究成果,由张雨舜、陈淙靓、李子牛、丁添、吴晨玮、Diederik P. Kingma、叶荫宇、罗智泉和孙若愚等人共同完成。
在这项工作中,研究团队通过分析 Transformer 模型的 Hessian 结构,提出了一种轻量化优化器 Adam-mini 。Adam-mini 大幅减少了 Adam 优化器中学习率的数量,在降低 50% 内存开销的同时保持了与 Adam 优化器相当甚至更优的性能。
相关研究成果已发表于 ICLR 2025,并在Medium、YouTube及Twitter等平台获多次关注解读。

1、背景
当前,大语言模型的广泛应用使得训练大型模型的内存开销成为研究者和企业面临的一大挑战。这主要归因于大语言模型广泛采用的 Adam 优化器(Adaptive Moment Estimation),其尽管性能卓越,但内存需求却极为高昂。具体而言,Adam 优化器在训练过程中需要额外存储两个状态变量:一阶动量 m 和二阶动量 v(即每个参数需要存储两组变量),从而显著增加了内存负担。
举例而言,训练一个 Llama 2-7B(70亿参数量)模型的内存占用大致如下:
- 权重参数:28 GB( 7B X 4 byte)
- Adam 状态变量:58 GB( 2 x 7B X 4 byte)
- 其他:激活值和梯度缓存等
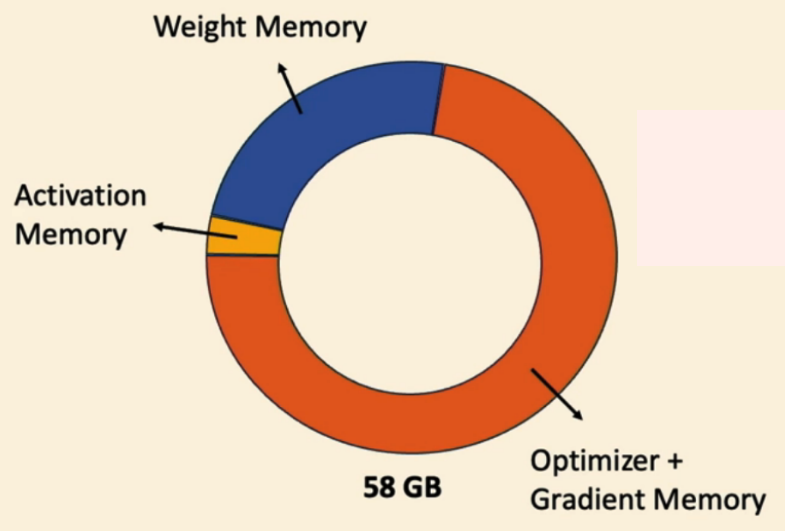
如此高的内存需求对硬件造成了巨大的压力,即便是顶级的 A100-80GB 显卡也难以直接承载,必须依赖内存分片或CPU卸载技术来分担负载。然而,这些额外的处理方式不仅显著增加了训练过程的复杂性,还加重了通信开销。
2、相关工作
因此,降低大模型训练的内存负担已成为学术界和工业界亟待解决的重要问题。针对这一挑战,近年来涌现了多种研究思路,包括低秩方法、轻量优化器、模型量化以及模型分片等。然而,现有的一些方法要么在训练过程中表现出性能不稳定,要么其总体效果无法与 Adam 优化器媲美。
图 1 直观展示了内存压力的主要来源——Adam 优化器中额外存储的两个状态变量。如果能在性能不变的前提下 减少优化器状态的数量,将显著缓解内存压力并提高训练效率。
3、关键发现:Hessian 块异质性
在探索为何 Adam 优化器在 Transformer 架构中性能远胜于 SGD 的过程中,我们于 2024 年发现了Transformer 架构中存在的 Hessian 块异质性(Block Heterogeneity)现象。相关研究成果已发表于 NeurIPS 2024 会议论文。
Definition [Hessian Block Heterogeneity]
Hessian 块异质性指的是,神经网络的 Hessian 矩阵在不同参数块之间的特征谱具有显著差异的现象。
如图 2(a) 所示,以 CNN 架构的 VGG16 为例,不同块(卷积层)的 Hessian 谱较为相似。然而,图 2(b) 表明,在 Transformer 架构的 BERT 中,不同块的 Hessian 谱差异很大 (比如特征值范围差异可超200倍)。
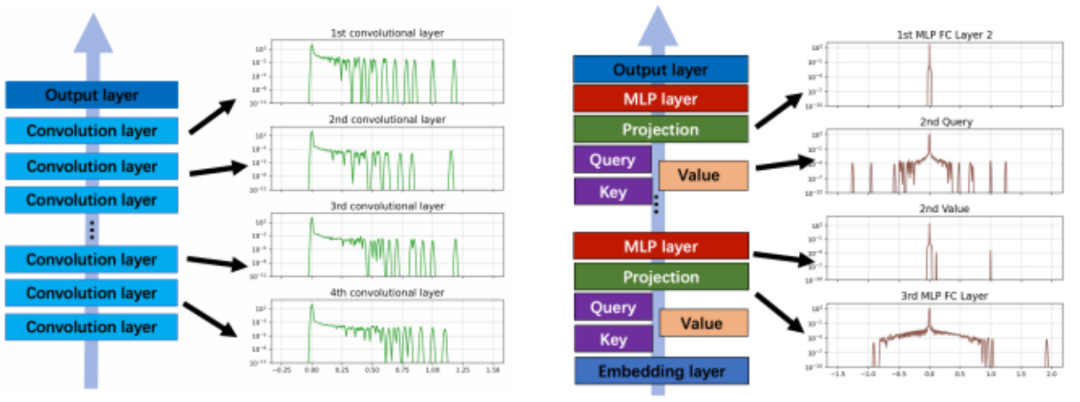
众所周知,在 CNN 模型中, SGD 与 Adam 性能相当;但是在 Transformer 模型中,SGD 的性能则显著逊色于 Adam。我们推测,这种性能差异在一定程度上源于 Hessian 块异质性。在大量真实任务和合成的异质性任务上 进行的实验表明, SGD 的性能会随着块异质性程度的增加而下降,从而进一步支持了这一推测。
具体来讲,我们将每个参数块的 Hessian 谱归一化为概率分布,并采用 JS distance 来度量分布之间的差异,从而定量描述块异质性的程度。如表 1 和图 3 所示,我们对若干模型在初始化时的 JS distance 进行了计算,得出了以下发现:
图 3 的趋势表明:
- JS distance 越大,块异质性程度越高, SGD 优化器的性能相较于 Adam 越差;
- Transformer 架构主导的模型,其块异质性程度是 CNN 的数百倍。
表 1:初始化时,成对参数块 Hessian 谱之间的 JS 距离(JS)

对此,我们的解释是,块异质性意味着不同的参数块有不同的优化需求,使用单一学习率的 SGD 难以适应多样优化需求,因此块异质性正是 Adam 在 Transformer 架构中优于 SGD 的关键原因。
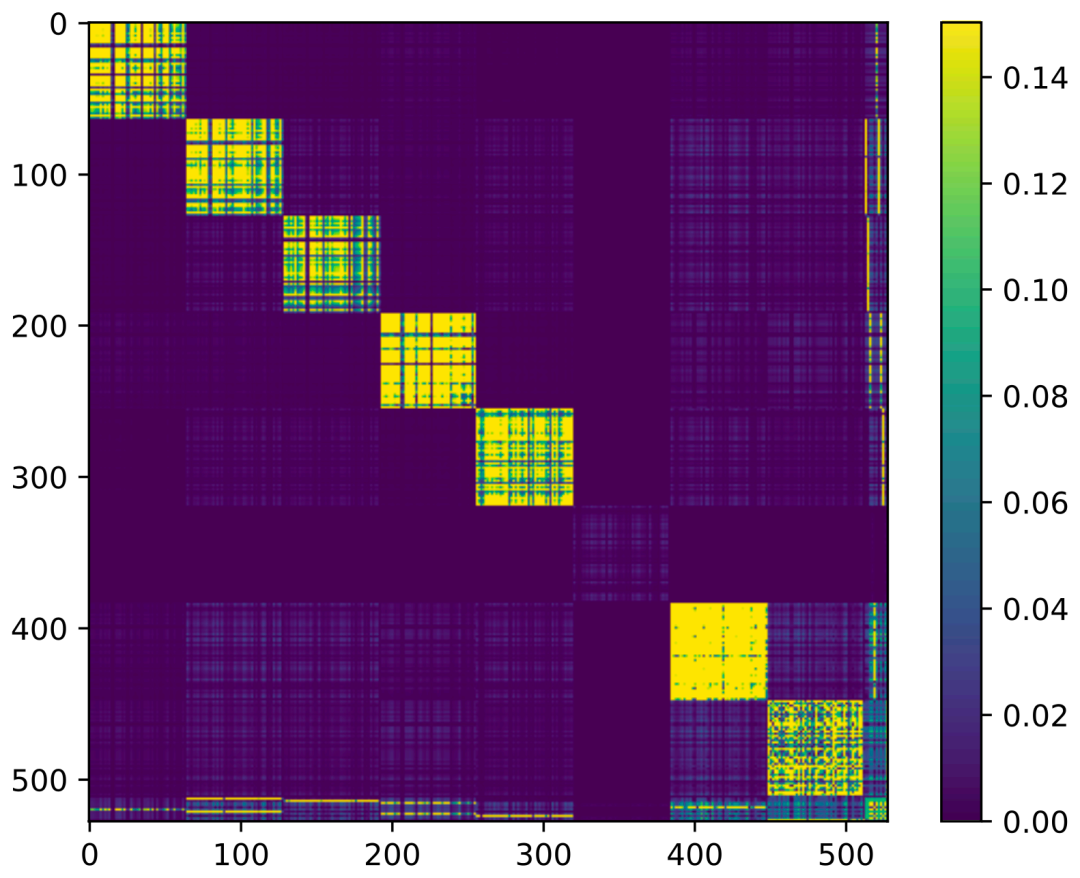
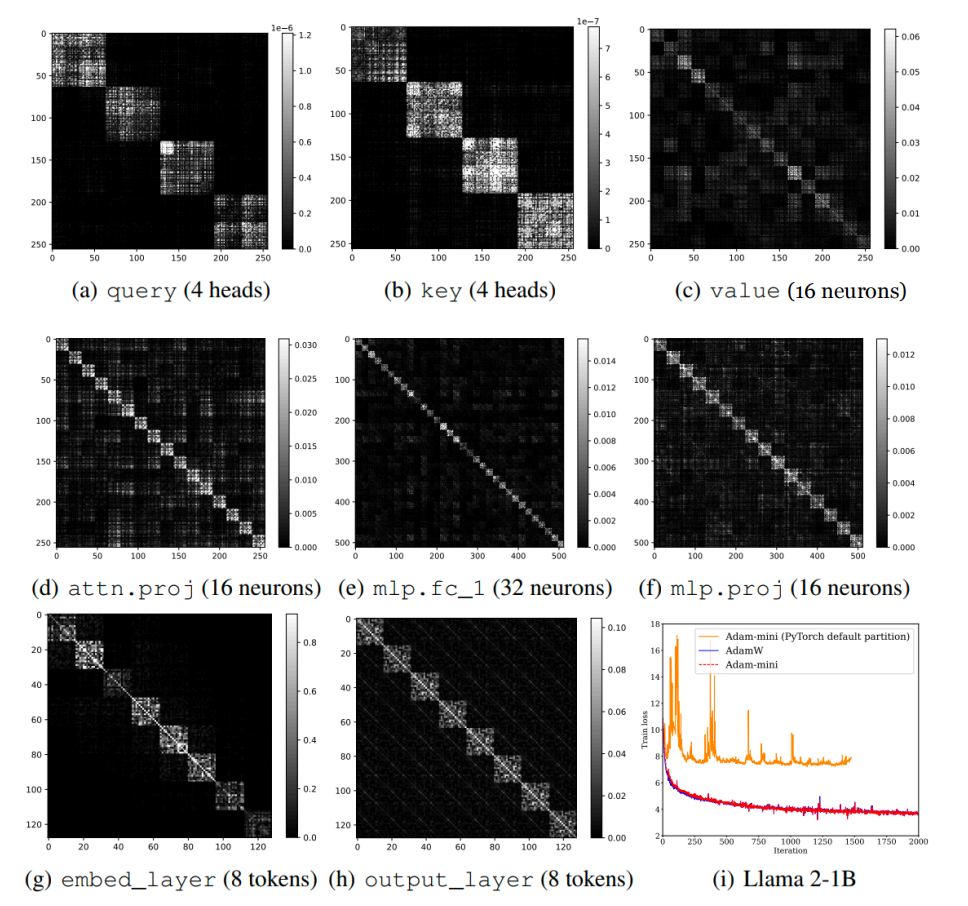
受块异质性现象的启发,我们进一步观察到 Hessian 的近似块对角结构(如图 4 所示)。这一结构在本文的主题 Adam-mini 优化器的设计过程中起到了关键作用。
4、轻量优化器:Adam-mini
回归本文主题,我们认为尽管 Adam 优化器性能优异,但其为每个参数单独分配学习率的设计缺乏充分的理论支 持。在大多数情况下,这种细粒度的学习率分配带来的可能并非性能的提升而是内存耗费的增加。
同时,此前的研究表明 Transformer 架构的 Hessian 矩阵通常呈现出近似块对角的结构。这种结构的存在意味着 相同参数块内的参数优化需求可能具有相似性,并无需独立分配学习率。
基于上述动机和观察,我们提出了 Adam-mini 优化器,相关研究成果已发表于 ICLR 2025会议论文[2],其核心设计思想如下:
1. 基于 Hessian 结构分块:对于 Transformer 架构, query 和 key 按 head 分块;value 、attn.proj 和 MLP 按输出神经元分块;embed_layer 和 output_layer 按 token 分块。
Remark:
(1)上述分块策略基于近似块对角结构的分析与实践经验的权衡设计。
(2)为便于理解,图 5 以一个小型 Transformer 为例,直观展示了该策略的有效性。
2. 简化学习率:取子块 b 梯度的均方值为唯一学习率,且在块内共享。
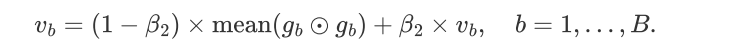
简单的理论分析表明, Adam-mini 可以无损地移除超过 99.9% 的二阶动量 v ,从而为 Adam 优化器节省接近 50% 的内存。
5、实验验证
我们从多方面对 Adam-mini 进行了实验评估,实验涵盖语言模型的预训练和微调任务,以下是主要结论:
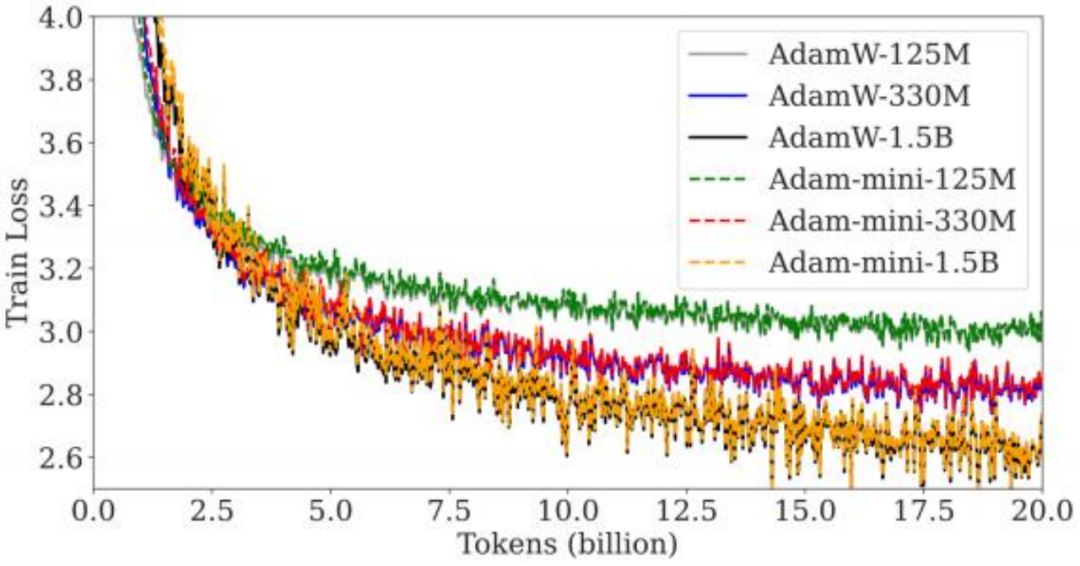
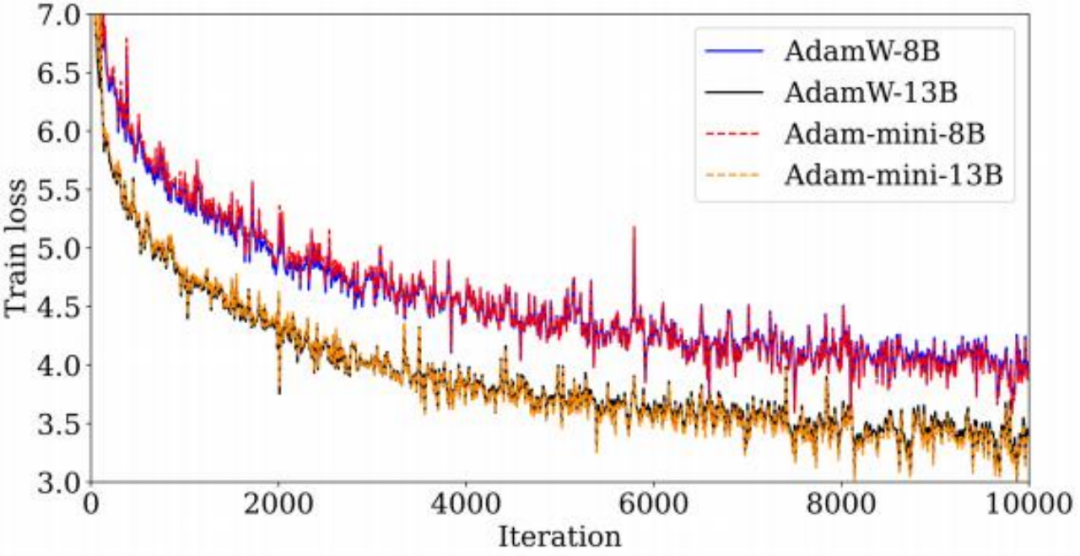
1. 大幅降低内存开销:在 GPT-2(图 6) 和 Llama 系列(图 7)模型的预训练中, Adam-mini 相比 AdamW 减少了 50% 的优化器状态内存开销。与此同时, Adam-mini 在多项指标上都与 AdamW 的表现持平,在某 些任务中甚至略优。
Remark:
Adam-mini 曲线逐渐与原始 Adam 曲线趋于重合的现象,可能表明 Adam-mini 以更少的内存保留了 Adam 的精髓。
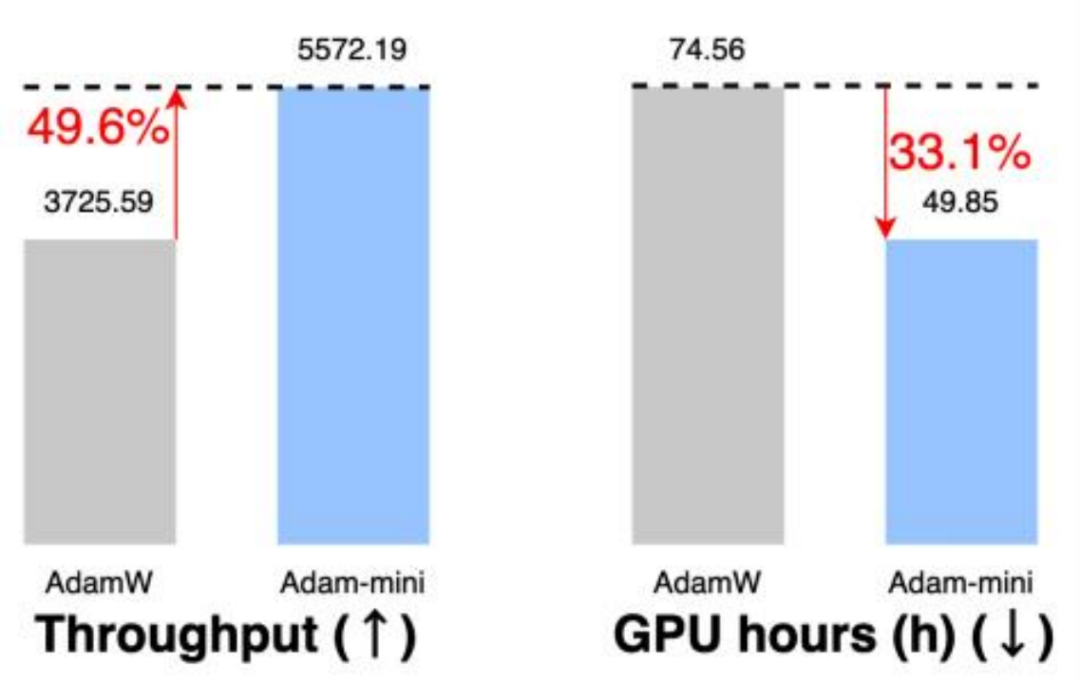
2. 提升吞吐量:如图 8 所示,由于减少了通信开销和内存占用, Adam-mini 在预训练 Llama 2-7B 模型时吞吐 量提升了 49.6% ,训练时间缩短了 33%。
3. 广泛适应性:在下游任务中,包括监督微调(SFT)和基于人类反馈的强化学习(RLHF),Adam-mini 在性 能上略优于AdamW,展现出了强大的适应性。
4. 超参数鲁棒性:Adam-mini 对学习率和其他超参数的选择不敏感,显著降低了调参难度。
6、Adam-mini的延伸:GaLore-mini
近年来,低秩方法已成为内存优化的一个有效方案,其中的代表作是 GaLore。我们注意到 GaLore 和Adam-mini 的技术思路在本质上是正交的,因此融合两者的核心思想,提出了全新的优化器 GaLore-mini(被 NeurIPS 2024 Workshop接收)。
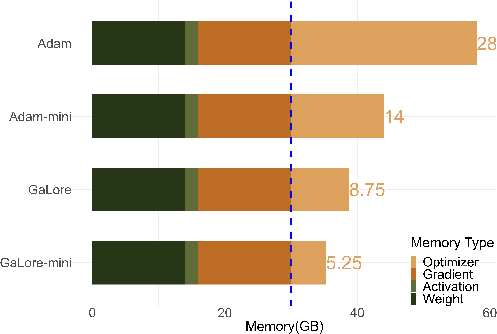
GaLore-mini 通过利用梯度的低秩特性,将梯度投影到低维空间来更新优化器状态,同时结合 Adam-mini 的策略,显著减少了优化器的存储需求,从而极大程度降低了内存开销。相较于 AdamW,GaLore-mini 在不损失性能的情况下实现了 81% 的内存节省。
各种方法的内存开销对比如图 9 所示。
7、总结
Adam-mini 的设计灵感来源于对优化器工作机制的深刻理解,以及对实际问题的敏锐洞察。它通过创新学习率分配机制,不仅显著降低了内存开销,还在性能稳定性上表现出色,并展现了极强的通用性。
此外,Adam-mini 与现有框架高度兼容,用户仅需一行代码即可轻松安装:

使用方法与 AdamW 类似:

如果您对本文内容感兴趣,欢迎访问 GitHub 项目主页了解更多详情。未来,Adam-mini 有望在大语言模型训练中发挥更重要的作用,为深度学习领域的资源效率优化提供新的思路。
