






PhysGen3D 实现了对静态图像中物体的三维重建、物理属性估计和用户驱动的动态模拟。
作者丨陈博远
你是否曾看着一张照片,想象“如果推一下这个苹果,它会怎么滚动?”或“如果捏一下这些毛绒玩具,它们会如何变形?”人类天生具备从静态图像推理物理动态的能力,但AI却长期难以实现这一认知飞跃。清华大学、伊利诺伊大学香槟分校和哥伦比亚大学的研究团队提出PhysGen3D,首个从单张图像构建可交互物理3D世界的通用框架。该框架通过整合几何重建、物理推理与仿真、真实感渲染等技术,实现了对静态图像中物体的三维重建、物理属性估计和用户驱动的动态模拟,在物理合理性、用户控制灵活性和渲染质量上超越现有图像到视频生成模型。
技术亮点:
- 单图输入:仅需一张RGB照片。
- 物理参数控制:调节弹性、摩擦系数、初始速度,兼顾自动推理和用户指定。
- 多材质仿真:支持不同软硬物体(如毛绒玩具和苹果)、颗粒(如沙子)。
- 灵活应用:支持更换场景

论文题目:
PhysGen3D: Crafting a Miniature Interactive World from a Single Image
论文主页:
https://by-luckk.github.io/PhysGen3D/
论文链接:
https://arxiv.org/abs/2503.20746
代码链接:
https://github.com/by-luckk/PhysGen3D
一、研究动机:突破静态图像理解的物理交互瓶颈
想象一下,当你看到一张静物的照片时,是否曾好奇:推一下这个物体它会怎么运动?按一下这个物体它会怎么变形?这些"假设性"问题背后,是人类对物理世界的直觉推演能力。然而,当前AI生成技术却面临两难困境——基于扩散模型的图像转视频(I2V)虽能生成逼真的视觉效果,却缺乏物理规律约束;而物理数字孪生技术虽能精确模拟交互,又受限于多视角数据采集的严苛要求。
现有AIGC视频模型(如Sora、Pika、Kling等)虽能生成惊艳的视觉效果,但用户无法精准控制物体的运动轨迹和物理属性,导致"所想未必所得"。另一方面,单图像物理建模方法常局限于刚体运动或特定物体类型,难以实现复杂场景的普适性交互。这种技术断层阻碍了AI对物理世界的深度理解与创造性应用。
为此,我们提出PhysGen3D,致力于突破单图像重建的物理交互瓶颈。通过融合视觉大模型的几何理解能力与物质点法
二、方法概述
我们的目标是从单张输入图像重建一个微型的3D可交互世界。该任务面临的核心挑战在于单视角观测的局限性,以及在缺乏动态观测数据时物理推理的欠定性。针对这些挑战,我们提出了一种整体重建方法,利用预训练视觉模型从单张图像联合推断几何结构、动态材质、光照和基于物理的渲染(PBR)材质参数。重建后的场景将被输入物质点法(MPM)仿真器,以生成逼真的物理现象。最后,我们基于仿真结果渲染动态物体行为,并将其重新整合到场景中,从而生成具有真实运动和视觉表现的视频。整体流程由下图展示。
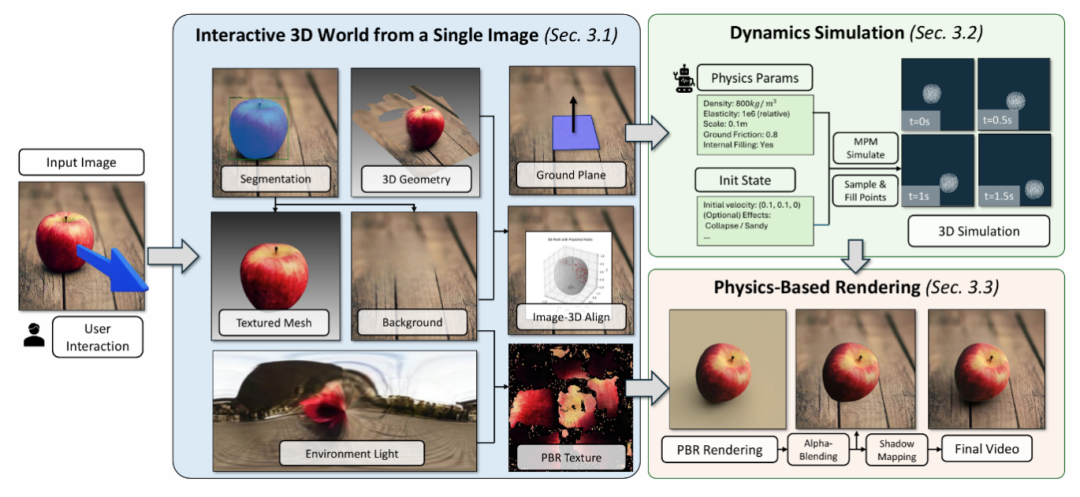
1、多模态联合重建
本框架采用多模态协同推理,突破几何重建、位姿估计、物理和渲染参数优化三大核心技术瓶颈,实现从单视角图像到物理可交互数字孪生的转化。
a) 几何解耦与重建
实例感知分割:利用GPT-4o
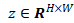
,使其尽可能地接近人类的注视轨迹S。利用LaMA
b) 物理约束的位姿估计
为解决生成的物体模型与恢复出的场景之间空间对齐的难题,提出两阶段优化策略。粗对齐:对每个生成的物体模型渲染多视角的图片,通过SuperGlue匹配渲染图和原图的特征点,采用PnP算法
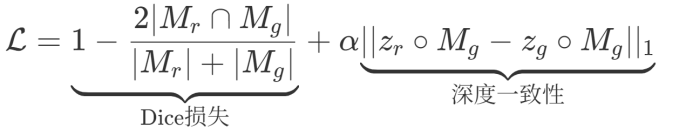
其中Mr、Zr为渲染结果,Mg、Zg为观测值。使用可微分渲染,精确对齐物体姿态。
c) 物理和渲染参数优化
物理参数推理:使用GPT-4o估计每个物体的密度、杨氏模量 E 等先验分布。同时为了统一仿真器的尺寸,使用了无量纲化的方法,利用特征长度消除尺度上的歧义。逆向材质优化:为实现光影一致性,使用Mitsuba渲染器
2、物理仿真引擎
在动力学仿真部分,我们使用已推理出物理属性和比例因子的3D资产,采用使用Taichi
a) 粒子表示
我们首先将3D资产转换为适合仿真的粒子表示。在这一过程中,我们去除数值不稳定的浮点、填充实体内部以确保物质连续性。我们还根据仿真器网格尺寸进行自适应的体素降采样处理。为了在保证仿真精度的同时优化渲染效果,我们优先保留表面的特征点。
b) 物理参数
为了确保仿真系统的稳定性,我们创新性地采用了对物理参数施加比例因子而非直接缩放资产尺寸的方法。具体而言,我们修正了重力加速度、弹性模量等关键材料参数,使用比例因子同步缩放。这种无量纲化处理使得系统能够在不损失物理真实性的前提下,适应不同尺度的仿真需求。在交互控制方面,系统支持根据用户输入的初始速度参数,为场景中的每个物体设置差异化的运动状态,从而实现精确的运动轨迹控制。
c)特效模拟
除了基础的物理仿真功能外,我们的系统还具备丰富的特效模拟能力。通过动态调整杨氏模量参数,可以逼真地模拟不同材质物体碰撞的效果;将材料类型切换为流体,则能实现物质熔融的视觉效果。这种灵活的参数调整机制赋予了用户极大的创作自由度,使其能够通过简单的参数修改,就实现多样化的物理效果模拟,大大拓展了系统的场景。
3、动态渲染合成
在完成动力学仿真后,我们获取了物体点的运动轨迹,并通过运动插值技术实现对三维mesh模型的动态形变处理。基于优化后的基于物理的渲染(PBR)材质参数,我们采用Mitsuba3渲染引擎在环境光照条件下进行物理渲染。借鉴前人在场景合成渲染领域的研究成果,我们创新性地避免了将整个静态背景导入渲染管线这一传统做法,而是通过背景深度图构建出一个专门用于捕捉阴影的三维表面。在具体渲染过程中,采用阴影映射技术来精确提取动态物体投射的阴影和全局光照效果。
最终,我们将经过物理仿真变形的前景物体与计算得到的阴影效果,通过图像合成融合到经过修复处理的背景图像上,从而生成具有真实光影表现力的最终视频输出。这种方法不仅提升了渲染效率,更确保了动态物体与静态场景在光照交互方面的物理一致性,使得合成结果在视觉上达到高度逼真的效果。
三、实验
1、实验设置
本研究的测试数据集涵盖多种图像来源,包括自主拍摄、网络图库及生成模型输出,主要是包含单个或少量物体的中心化场景。出于方法的局限性,我们排除了物体数量过多、深度交叠遮挡或表面几何剧烈起伏的复杂场景。在后处理环节,我们引入VEnhancer增强模块作为可选流程,该模块能对生成的视频进行修复,可以部分提升画面的细节表现力,但定量实验也表明其可能引入非物理的伪影。在基准选择上,由于现有物理仿真方案均需多视角输入或特殊场景配置,我们主要与主流的图像转视频(I2V)模型进行对比:开源运动控制模型DragAnything、MOFA-Video及商业级模型Kling 1.0通过人工标定运动轨迹实现精准控制;Gen-3与Pika 1.5则采用文本描述驱动,其中Pika 1.5额外支持"融化""收缩"等特效。
2、定性结果
我们的系统能够从单张图像生成微型交互世界,实现多样化物理现象的仿真模拟。下图中,系统成功处理了包含单物体、多物体以及刚体/软体等不同材质类型的输入图像,并生成相应动态视频。
对比实验:我们从运动控制与物理材质两个维度进行对比分析。下图对比了我们的模型和两个闭源的视频生成模型,本系统在物理真实性与可控性方面展现出显著优势。基于学习的模型即使经过提示词调优,仍常出现违背物理规律或用户意图的虚假生成现象。
动态调控:下图展示了同一输入图像在不同参数配置下的多样化动态生成效果。左侧三组实验保持物体初始位姿与速度一致,仅调整两个物体的弹性参数,呈现出从刚性碰撞到弹性振荡的连续变化;右侧三组则固定物理参数,通过改变速度方向产生截然不同的运动轨迹,验证了系统对动力学参数的高精度控制能力。
场景编辑:如下图所示,本方法支持对生成视频进行物体移除、添加与替换等编辑操作。得益于显式三维表征,重建的3D资产可被灵活操控。例如将两个场景中的物体互换,保持了物理交互的连贯性。
运动追踪:基于显式三维表征与粒子物理模拟器的协同工作,本框架可生成附带精准三维运动追踪数据的视频。下图中的两个案例分别展示了刚体旋转轨迹与软体形变场的追踪结果。
3、定量结果
为评估生成视频的质量,我们构建了人工评测、GPT-4o自动评估与VBench标准化指标复合评价体系。针对人工与GPT-4o评估,我们制定了三项核心指标:(1)物理真实感(PhysReal):衡量视频是否符合物理规律,以及弹性、摩擦等材料属性的真实表现;(2) 照片真实感(Photoreal):评估视频的视觉质量,包括光影连贯性、材质细节还原度与伪影控制;(3) 语义一致性(Align):检验生成内容与文本提示的意图匹配程度。此外,我们选取VBench中的运动平滑度与成像质量作为量化指标。我们设计了包含27个场景的视频评测集,涵盖不同运动条件与特效类型。
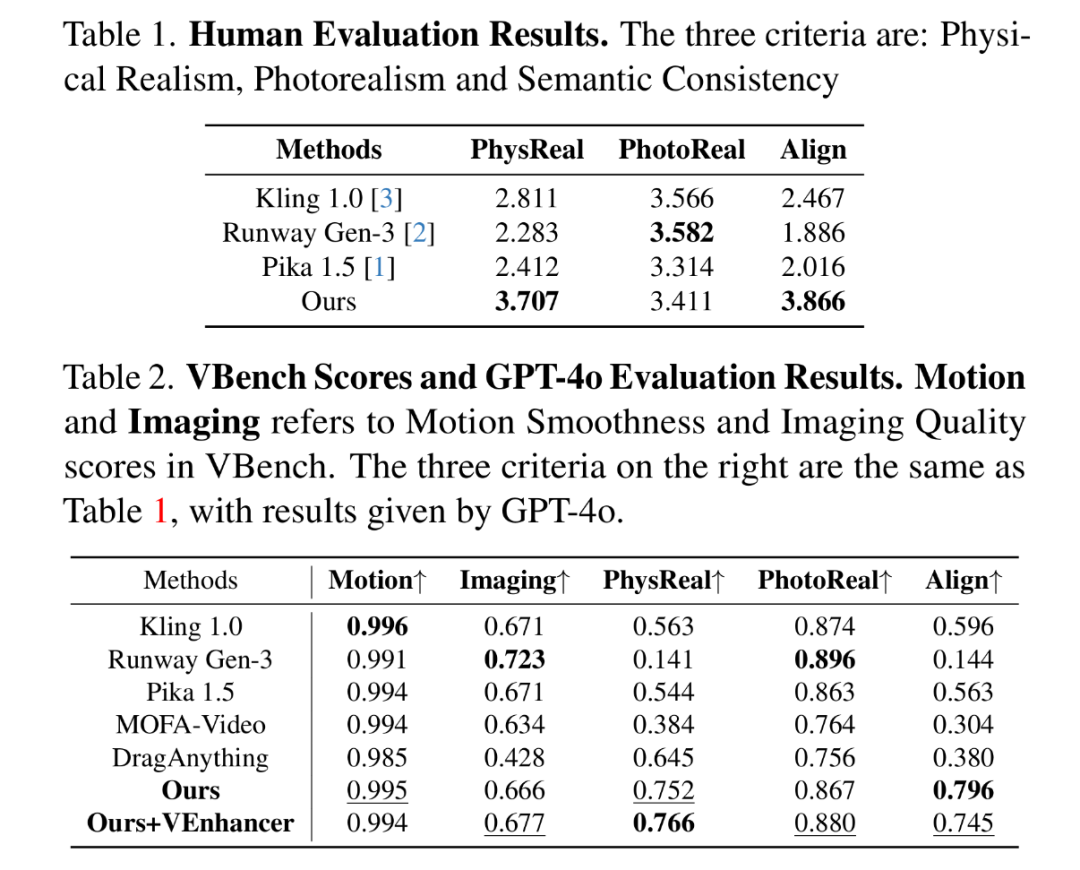
如上表展示的,本方法在物理真实感(PhysReal)与语义一致性(Align)指标上均显著优于所有商业模型,其中GPT-4o评估结果与人工评测趋势一致。本方法在物理合理性维度领先开源模型达37.5%。VBench数据显示,本方法的运动平滑度(0.82)与成像质量(0.79)均达到SOTA水平。在基线模型中,Kling 1.0凭借"运动笔刷"的轨迹控制功能表现最佳,但其物理真实感得分(3.12)仍低于本方法,凸显了物理仿真引擎的独特优势。
四、局限性和总结
本文提出的PhysGen3D框架主要适用于以物体为主的图片,且要求场景空间结构相对简单,对于包含复杂几何关系与多重交互的全局场景重建仍存在理论瓶颈。
我们实现了从静态图像到可交互物理场景的跨维度转化,通过三维重建、动态仿真与物理渲染的三元协同,形成了物理规律驱动的可控视频生成新范式。我们的研究在运动真实性与材质多样性方面实现显著提升,期待后续研究在复杂场景重建、多物体交互等方向取得突破,推动数字孪生技术的纵深发展。
