






MARFT 微调后的大语言模型多智能体系统性能优于未经微调的系统性能和单智能体 PPO方法,这在数学任务上得到验证并提升显著。
作者丨廖俊威、温睦宁
近期,基于大型语言模型(LLM)的多智能体系统(LLM-based Multi-Agent Systems, LaMAS
该论文详细介绍了 MARFT 的核心实现,强调了其模块化和适应性,并提供了完整的开源代码,以促进采用和进一步研究,具体见如下论文与代码链接。

arxiv link: https://arxiv.org/abs/2504.16129
github repo: https://github.com/jwliao-ai/MA
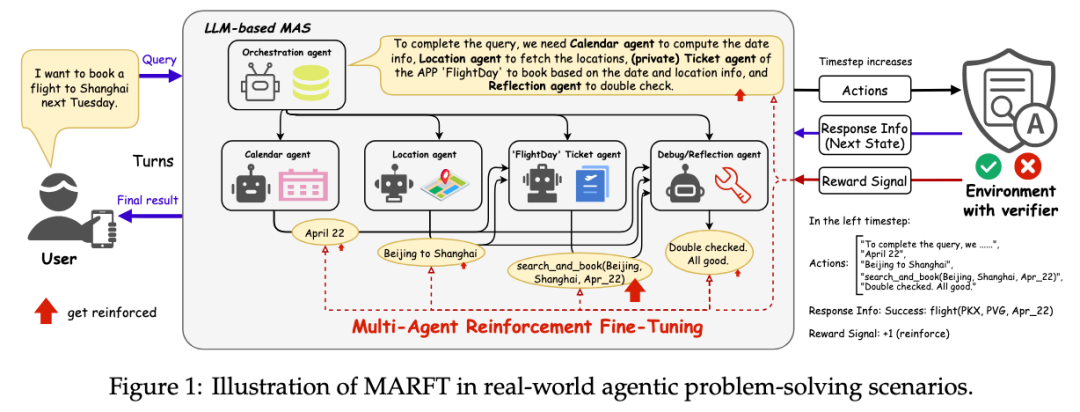
1、研究背景:以LLM为基础的多智能体强化微调的研究空缺与困境
随着大规模语言模型(LLM)被部署为新一代自主智能体,其在自主任务处理领域崭露头角。然而,将强化学习微调(RFT)应用于 LLM 多智能体系统(LaMAS)时,面临诸多挑战。一方面,RFT 在提升单智能体 LLM 性能上成果斐然,但目前缺少基于强化学习试错学习本质的多智能体强化微调方法,另一方面,LaMAS在解决实际问题时存在高度的组织动态性,传统多智能体强化学习(MARL)框架难以适配 LLM 多智能体系统的独特复杂性,现有框架在整合 LLM 作为动态环境中的智能体执行代理任务时存在缺失,限制了 LaMAS 的群体智能发挥。譬如一个针对软件开发的LaMAS可能需要分别完成“需求实现”和“代码纠错”两个子任务,但二者涉及的智能体集合与工作流程均可能不同;这对于传统MARL而言可能是个很少被考虑的情况,但在LaMAS里则十分常见。
2、基于大语言模型的多智能体强化微调 —— MARFT
在正式提出 MARFT 前,文章先对 RFT、LaMAS 和 MARL 进行了系统性的回顾,列举出了 RFT 与 RL 的不同点以及 MARFT 与 MARL 的不同点。研究团队创新性地提出了 Flex-POMDP <V,N,S,O,A,T,R,r,D>,该部分可观测马尔可夫决策过程(POMDP)考虑到 LaMAS 执行决策时智能体之间可能存在某种结果依赖关系,引入了动态依赖函数D,D(a, a) = 1 表示智能体 j 的决策依赖于智能体 i 的决策。该函数具有高度动态性,在每一个时间步都有可能不同,这取决于预先定义的 LaMAS 解决实际问题的机制或者 LaMAS 中的协管智能体。例如,在图 1 展示的时间步中,该依赖函数由协管智能体给出,订票智能体的决策则依赖于日历智能体与位置智能体。当状态依赖函数对所有智能体i、j 均为0时,Flex-POMDP退化为 DEC-POMDP,证明了 Flex-POMDP 的通用性。同时,为了更好地从微调角度剖析 LaMAS,文章对 LaMAS 进行了是否参数共享、是否异步决策和是否同时更新参数的讨论,为下文针对 LaMAS 的 MARFT 做铺垫。
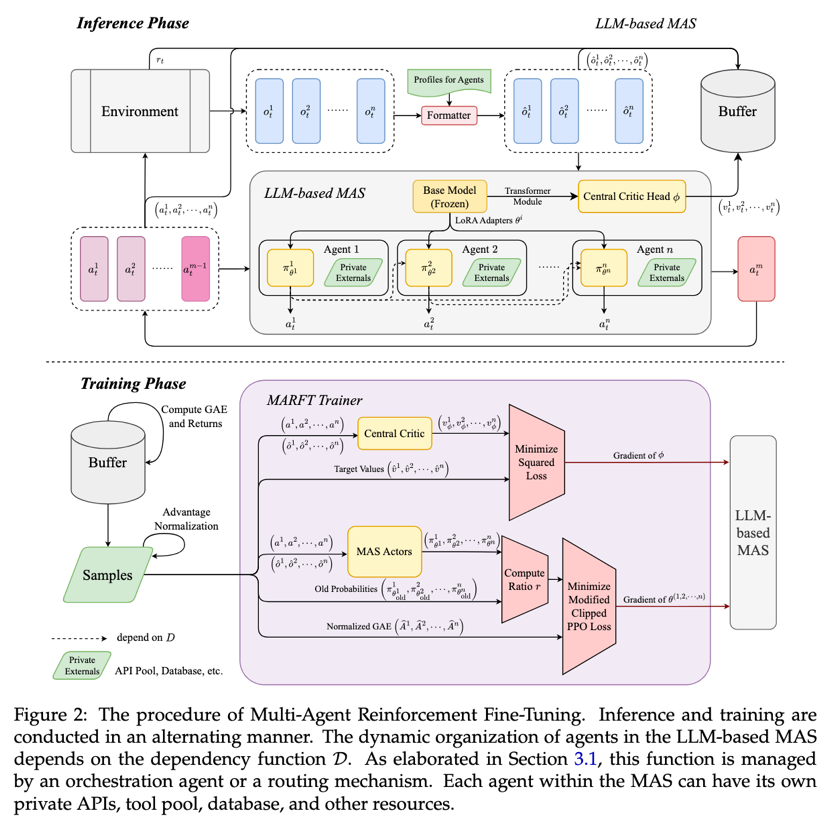
MARFT 采用 On-policy 算法框架,推理与训练交替进行,使用当前最新的策略生成轨迹数据,并用这些轨迹数据来微调 LaMAS。该论文提供了一种示例的实现方案(为了方便,后续直接称为 MARFT)。MARFT 通过多智能体优势值分解,将具有任意组织或动态依赖关系的多智能体微调重新建模为多智能体的序列决策微调,这很好地缓解了 LaMAS 面对实际问题时高度动态性所导致的优化复杂度过高的问题。MARFT 采用了类 Transformer
在基础算法的基础上,研究团队还讨论和实现了正则化、智能体顺序更新以及 Token 层面的 MARFT。
3、初步试验结果及分析
研究团队在MATH任务上进行了初步的验证,并对初步的实验结果进行了深入的分析和讨论。
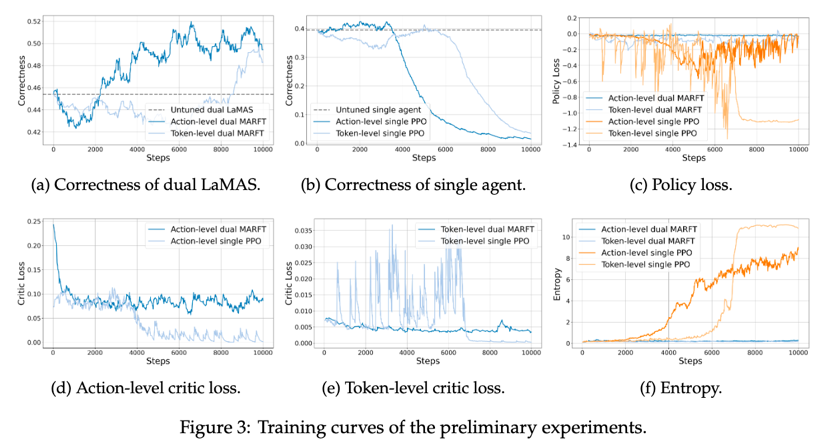
1. 单智能体 vs 多智能体
从单智能体和多智能体的训练曲线图可以看出,LaMAS(大规模多智能体系统)得益于群体智能,其基线性能和优化后的性能均优于单智能体方法。与此同时,与单智能体 PPO 相比,MARFT 展现出更好的稳定性。单智能体 PPO 尽管在训练初期有所提升,但随着训练的进行,其性能逐渐崩溃。而 MARFT 的正确率达到了大约 50%,比基线高出约 5%。
2. 动作级别微调 vs Token 级别微调
对比动作级别微调和 Token 级别微调的训练曲线可以看出,Token 级别微调在大约 8k 步之前表现出早期的波动,之后其准确率飙升至约 0.49,比未调整的双智能体 LaMAS 高出约 5%。这与文中解释的训练 Token 级别价值函数的挑战一致,即 Token 级别价值函数最初难以训练,导致早期阶段出现波动,这一点也在价值函数的训练曲线中有所体现。
3. 异常实验曲线
在初步试验曲线中,单智能体 PPO 在动作级别和 Token 级别微调中分别在 3k 步和 6k 步后出现了显著的性能崩溃。通过观察其输出熵的训练曲线图,研究团队发现熵值出现了大幅波动,这导致了梯度爆炸,进而引发了模型崩溃。这种现象是使用强化学习训练 LLMs 时的常见挑战,通常源于方差过大,并且智能体容易探索到无效 Token,而价值函数无法给出准确的价值。尽管这一问题难以完全消除,但可以通过从稳定的检查点恢复训练、调整上下文 epsilon 的值等方式来缓解。
除此之外,研究团队还对将来的实验进行了详细规划,具体包括将 MARFT 扩展到更多更困难、更能体现 LaMAS 代理能力的任务上,逐步增加智能体数量等。
4、前景与挑战
文章在方法与实验部分结束后,对 MARFT 的发展前景提出以下几点:
1. 复杂任务解决能力出色:MARFT 借助强化学习微调(RFT),使基于大型语言模型(LLM)的多智能体系统(LaMAS)在解决复杂任务方面表现出色。它能高效分解复杂指令为子任务并分配给各智能体,这些智能体通过自然语言交互,动态共享目标、协商策略及协调行动。在物流场景下,可优化智能体协作,实现应急物资高效配送。
2. 可扩展性和鲁棒性良好:MARFT 可适应多智能体问题的灵活性,智能体数量、环境复杂性和任务规模增加时,通过动态任务分解与智能体角色调整,在变化组织结构下仍能高效运行,面对复杂多变任务可保持稳定性能和高效协调能力。
3. 具备隐私保护优势:MARFT 的多智能体系统中,智能体不共享本地私有数据,仅通过行为贡献集体智慧,与联邦学习理念相似,但更注重协作提升系统性能,在隐私敏感场景有天然优势。
4. 与区块链技术融合度高:MARFT 的去中心化特性和隐私保护能力契合区块链技术,在智能合约执行等场景中,可实现安全高效协作,无需共享敏感数据,其动态适应性和保留预训练能力的特点,使其在区块链的不确定性和对抗性环境中表现出色。
同时,研究团队为MARFT接下来的研究指出了几个潜在方向:
1. 动态训练环境缺失:推动 MARFT 面临的一大难题是缺少用于解决代理任务的动态交互环境,该环境需易于实现且可扩展。一方面,构建含复杂代理任务的环境需大量工程专业知识;另一方面,在高度动态环境中为多智能体系统设计奖励反馈机制极为困难,奖励信号多维,平衡不同目标权重很精细。当下虽有部分 “动态” 基准测试,但将其转化为支持 MARL 训练的动态环境仍是待解问题。
2. 样本效率低与缺乏优质合成数据:强化学习样本效率低,像 PPO、TRPO 算法需频繁在采样轨迹与训练间切换,应用于 LLM 时更耗时低效。且样本效率低导致缺乏高质量合成数据,有效的多智能体轨迹需高成功率及高效的沟通协作,目前该领域缺少用于多智能体冷启动的此类数据。
3. MARFT 框架需进一步完善:整合 LLM 和 MARL 的工程解决方案极具挑战,虽有 OpenRLHF
4. 通信机制或协议不统一:近年出现诸多智能体通信协议,如 MCP、A2A 和 ANP,这些协议对促进智能体有效协作、与用户互动至关重要,也满足智能体保留自身数据和知识的需求。但协议众多导致碎片化格局,缺乏统一高效通信管道,阻碍不同智能体在 LaMAS 动态异构环境中的无缝集成与互操作,还使系统设计、可扩展性复杂化,引入低效和潜在瓶颈。
5、研究贡献总结
在文章的最后,研究团队对整篇文章进行了总结,该工作的主要贡献有:
- 提出了一种新的多智能体强化微调范式MARFT并给出了一种完整的开源实现:MARFT框架是针对基于大型语言模型(LLM)的多智能体系统(LaMAS)的强化微调而提出的,它在理论和实践上都具有创新性。该框架能够有效应对LaMAS的独特复杂性,填补了现有研究的空白。此外,研究团队开源了MARFT的完整代码并进行了深入的分析,这不仅有助于其他研究人员快速上手和验证MARFT的效果,还能够推动该领域的快速发展。
- 探讨了MARFT的发展前景和挑战:文章不仅提出了 MARFT 的当前成果,还对其未来的发展方向和面临的挑战进行了深入分析。MARFT 在解决复杂任务、提升系统可扩展性、保护隐私以及与区块链技术融合等方面展现出巨大的潜力。然而,当前研究仍面临诸多挑战,如缺乏动态训练环境、样本效率低下、缺乏高质量合成数据、以及缺乏完善的 MARFT 框架和统一的智能体通信机制。这些挑战为后续的研究工作提供了明确的指引,有助于推动 MARFT 在更广泛的应用场景中发挥作用。
