






PaCo-RL:基于成对奖励与强化学习的图像一致性生成方法。
作者丨郑佳美
编辑丨岑 峰
很多人都有这样的体验:让 AI 画一个角色,第一张很好看,但第二张开始有点不一样,第三张基本就像换了个人。你让它做一套海报,单张都不错,但放在一起风格却完全不统一,再或者你让它画一个故事分镜,人物形象会一会胖一会瘦,甚至连脸都对不上,你只是改一下衣服颜色,它却顺手把脸也改了。
这些看起来像小问题,但在真实应用中却是致命的。在 IP 设计、品牌视觉、内容生产甚至工业和医疗场景中,要求的从来不是某一张图好看,而是一整组都要一致。
问题的关键在于,当前图像生成模型虽然已经从“能用”走向“高质量”,但能力仍停留在单次生成优化,也就是“单样本最优”。它擅长把一张图画好,却不知道哪些东西必须在多张图之间保持不变。换句话说,模型缺少的不是生成能力,而是一种对跨图关系的稳定建模能力,而这一能力,正是生成模型走向规模化应用的关键瓶颈。
在这一背景下,来自西安交通大学与新加坡 A*STAR 的研究团队提出了论文《PaCo-RL: Advancing Reinforcement Learning for Consistent Image Generation with Pairwise Reward Modeling 》,从建模范式层面对这一问题进行重构。
这项研究没有沿用传统的单图打分或图文对齐思路,而是将一致性问题转化为“跨图比较”的学习问题,通过构建成对比较的奖励模型,使模型能够学习人类在判断一致性时所依赖的相对关系与多维标准,并进一步结合强化学习,将这种判断能力反向作用于生成过程之中,从而实现从“会判断”到“会生成”的能力闭环。

论文地址:https://arxiv.org/pdf/2512.04784
01
从「不会判断」到「 稳定生成」
整体来看,实验结果可以归纳为一条完整且有数据支撑的逻辑链。
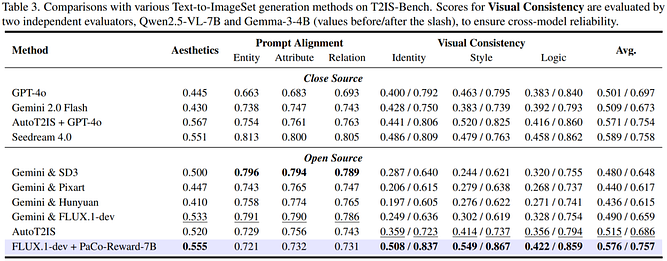
首先,研究团队通过对比实验发现,现有模型并不具备真正的图像一致性理解能力。在 ConsistencyRank 基准测试中,大模型 Qwen2.5-VL-7B 的准确率仅为 0.344,而传统方法 CLIP-I 和 DreamSim 分别达到 0.394 和 0.403,反而表现更好,同时在排序相关性指标上也明显领先。
这说明通用大模型虽然具备较强的图文理解能力,但在需要跨图比较并综合身份、风格和逻辑等多维因素的一致性判断任务中存在明显不足,因此一致性属于一种无法通过通用能力直接获得的专门能力。
在此基础上,研究团队训练了 PaCo-Reward 模型,并在同一基准上测试,结果显示准确率提升至 0.449,相比原模型提升超过 10%,同时在 Spearman 相关系数上也达到 0.288,显著优于所有对比方法,说明这一模型在排序能力上更接近人类判断标准。

进一步地,在 EditReward-Bench 测试中,PaCo-Reward 在一致性指标上达到 0.709,在整体指标上达到 0.751,不仅超过所有开源方法,而且接近 GPT-5 的表现,说明模型具备良好的跨任务泛化能力,而不是简单记忆训练数据。在此基础上,研究人员将这一奖励模型引入强化学习训练,在生成任务中进一步验证性能提升。

在 Text-to-ImageSet 任务中,一致性指标整体提升约 10.3% 到 11.7%,在身份、风格和逻辑等多个维度均有明显改善,同时在 GEdit-Bench 图像编辑任务中,语义一致性和提示质量指标均持续提升,例如在 Qwen-Image-Edit 模型上,整体分数从 7.307 提升至 7.451,在多语言设置下也表现出一致的改进趋势,这说明模型不仅能够提升一致性,还能够保持甚至提升生成质量。
在训练效率方面,研究发现采用低分辨率训练策略时,512 分辨率训练大约 6 小时即可达到与 1024 分辨率约 12 小时训练相当的效果,在约 50 个训练轮次后性能基本收敛一致,显著降低计算成本。
在训练稳定性方面,传统多奖励加权方法会导致奖励比例在训练过程中迅速超过 2.5,从而出现单一奖励主导优化的问题,而改进方法能够将奖励比例稳定控制在 1.8 以内,从而避免优化偏移并保持多目标平衡。
综合以上实验结果可以得出结论,研究不仅成功训练出能够准确建模人类一致性判断的模型,而且能够将这一能力有效用于生成模型优化,并在保证训练效率和稳定性的前提下实现性能提升,从而形成一个完整且可行的技术闭环。
02
从可解释判断,到可控生成
整个实验过程可以清晰地划分为两个阶段。第一阶段围绕如何判断图像一致性展开。研究团队首先发现缺乏可以直接用于训练一致性判断的数据,其根本原因在于一致性本身具有较强的主观性,同时涉及身份、风格和逻辑等多维度因素,很难通过统一标准进行标注。
因此,研究人员设计了一套结合自动生成与人工标注的数据构建流程。具体而言,首先利用生成模型构建数据源,通过生成约 2000 条文本 prompt,并进一步筛选出 708 条具有代表性和多样性的 prompt,然后基于这些 prompt 使用图像生成模型生成具有内部一致性的图像网格,每个 prompt 会生成多个图像网格,每个网格包含多个子图。
接下来进入关键步骤,即对子图进行拆分与组合,也就是将每个图像网格划分为多个 sub-figure,并在不同网格之间进行组合,从而构造出大量具有不同一致性关系的图像对。这一过程通过组合方式显著扩大数据规模,在约 708 个 prompt 和 2832 张图像的基础上构造出 33984 个排序样本。

随后,研究人员构建排序任务,每个样本包含 1 张参考图和 4 张候选图,标注任务是根据视觉一致性对候选图进行排序。标注过程由 6 名标注人员完成,每人标注约 5664 个样本,标注过程中不依赖严格规则,而是基于人类直觉对一致性进行判断,同时保留部分数据作为评测基准。
为了便于模型训练,研究团队进一步将排序数据转换为 pairwise 数据形式,即将排序关系转化为两两比较的样本,例如将多个候选之间的排序关系拆解为多个 A 与 B 的一致性判断,从而得到超过 54624 个图像对,其中包括 27599 个一致样本和 27025 个不一致样本,每个样本不仅包含标签,还配有对应的推理解释,从而增强数据的可解释性与泛化能力。
在完成数据构建之后,研究团队进一步设计奖励模型的训练方式。传统方法通常采用输入图像并输出一个标量分数的方式来表示质量或一致性,但这种方式与视觉语言模型基于自回归生成的机制不匹配,同时难以表达复杂判断过程。
为了解决这一问题,研究人员提出将一致性判断建模为生成任务,在 PaCo-Reward 模型中,输入由两张图像和对应文本组成,模型输出为 Yes 或 No,用于表示两张图像是否一致,同时还会生成一段推理过程来解释判断依据。这一设计使一致性判断转化为语言生成问题,从而能够直接利用视觉语言模型的生成能力进行训练,并提升模型稳定性与可解释性。
模型在训练过程中不仅学习最终的判断结果,还学习推理过程,从而避免仅依赖表面特征进行判断。完成训练后,研究人员通过排序一致性任务和图像编辑任务对模型进行验证,结果表明这一奖励模型在多个指标上均优于现有方法。

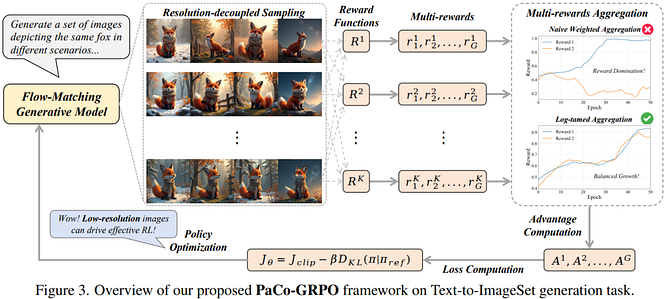
第二阶段围绕如何生成一致图像展开。研究人员在这一阶段引入强化学习框架,其基本流程包括模型根据输入生成图像集合,然后由奖励模型对生成结果进行评分,再根据评分信号更新生成模型参数,这一过程类似人类通过反馈不断优化行为的学习方式。
在具体实现中,研究团队提出了两个关键优化策略以提升训练效率与稳定性。首先是分辨率解耦策略,即在训练阶段使用低分辨率图像进行采样与优化,而在推理阶段仍然生成高分辨率图像,这样可以显著降低计算开销,因为图像生成模型的计算复杂度与分辨率呈平方关系增长,而实验表明低分辨率图像已经能够提供足够的奖励信号来指导优化方向。
其次是奖励平衡策略,用于解决多目标优化中的冲突问题。在一致性生成任务中,模型通常需要同时优化一致性与文本对齐等多个目标,而不同奖励之间可能存在尺度差异和波动差异,从而导致某一奖励在训练过程中占据主导地位。为了解决这一问题,研究人员对波动较大的奖励进行压缩处理,从而降低其影响范围,使多个奖励在优化过程中保持相对平衡,避免训练偏移。
最终,研究团队在多图生成任务和图像编辑任务上对方法进行验证,结果显示模型在身份一致性、风格一致性以及逻辑一致性等多个方面均得到明显提升,同时在编辑任务中能够实现局部修改与整体保持之间的良好平衡,从而验证整个方法在实际生成任务中的有效性。

03
从单点生成到关系建模的范式变化
这项研究的意义不仅体现在技术层面,也正在改变普通人使用 AI 的体验。首先在问题层面,研究团队解决了多图一致性这一长期存在的难题。过去人工智能模型虽然可以生成单张高质量图像,但一旦需要连续生成角色、设计系列海报或制作故事分镜,就会出现人物变化、风格不统一甚至逻辑混乱的问题。
这意味着普通用户即使生成了好看的图片,也很难真正用在创作、设计或内容生产中。而通过系统性的设计与训练,这项研究让模型能够在多张图像之间保持一致,使 AI 从“能用”走向“可用”,真正具备连续创作能力。
在方法层面,研究提出了一种更接近人类思维的学习方式,即通过比较来学习,而不是直接打分。对于普通用户来说,这种变化意味着模型更“懂人”的审美和判断标准,不再只是机械优化指标,而是能够更自然地理解“像不像”“一致不一致”这样的主观概念,从而生成更符合人类预期的结果。
在训练层面,研究进一步推动了强化学习在图像生成中的实际应用。过去这类方法往往成本高、训练不稳定,难以真正落地,而研究通过低分辨率训练与奖励平衡机制,在降低计算成本的同时提升稳定性。这不仅提升了模型性能,也意味着未来类似能力可以更快进入产品,普通用户在工具中直接体验到更稳定、更一致的生成效果。
更深层来看,这项研究构建了一种生成与评价相结合的闭环机制。传统模型只负责“生成”,而在这一方法中,模型不仅能够生成图像,还能够在生成过程中不断“自我检查”和优化结果。
对于普通人而言,这意味着未来的 AI 不再需要反复手动调整提示词,而是可以自动修正偏差,逐步生成符合预期的内容,从而大幅降低使用门槛。
04
构建 PaCo-RL 的人
这篇论文的共同一作分别是平博文和贾成铕。其中,贾成铕目前是西安交通大学计算机科学专业博士研究生,处于博士阶段后期,导师为罗敏楠教授,同时与常晓军教授开展合作研究,并且未来将加入腾讯混元的青云计划从事研究工作。在科研经历方面,贾成铕曾在新加坡进行访问研究,并在上海人工智能实验室担任研究实习生。
在学术成果方面,贾成铕已在多个国际顶级会议和期刊发表论文,包括 CVPR、AAAI、ACL、IEEE TIP 等,同时担任 NeurIPS、ICML、CVPR、ECCV 等重要会议与期刊的审稿人,体现出较高的学术影响力与认可度。
在研究方向上,主要从事计算机视觉与多模态领域的研究,重点关注视觉生成与智能体相关问题。具体研究内容包括一致性图像生成、视频生成,以及奖励模型与强化学习在视觉生成中的应用,整体目标是提升模型在生成任务中的一致性、可控性与智能性。

参考地址:https://chengyou-jia.github.io/
这篇论文的通讯作者钱航薇,目前在新加坡 A*STAR 前沿人工智能研究中心从事研究工作。
在研究方向方面,钱航薇主要从事人工智能与多模态学习相关研究,重点包括多模态大语言模型、面向科学研究的人工智能、生成式人工智能与智能体系统,以及基于大模型的科学发现方法,同时还关注可信与可解释人工智能以及时间序列建模等方向 。
在科研成果方面,钱航薇在 AAAI、IJCAI、KDD 等国际会议以及人工智能领域重要期刊发表多篇论文,研究内容涵盖对比学习、强化学习、时间序列建模以及可解释性等方向,并参与多个科研项目,包括 A*STAR Career Development Fund 和相关研究基金项目 。

